[k8s 스터디] #05 Application 기능 이해하기 Probe
프로브 자세히 알기
프로브는 특정 url로 요청을 보내 잘 동작하는지 확인하는거
startupProbe
readinessProbe
livenessProbe
가 있는데 보통 모두 동일한 요청을 보내게 만듬(의문 포인트 1)
livenessProbe랑 readinessProbe는 둘다 동일하게 장애발생 시
동일하게 실패하는데 왜 둘을 별개로 써야하나(의문 포인트 2)
의문포인트를 해소해가면서 Probe를 알아보자
Application 로그를 통한 프로브 동작 분석
실습 전 사전 준비작업 → HPA minReplica 1로 변경
HPA는 가용성을 위해 파드의 개수를 조절해주는 오브젝트
만약 파드가 2개 이상이면 로그 분석하기 힘드니까 하나의 파드만 나오게 변경하는것
kubectl patch -n anotherclass-123 hpa api-tester-1231-default -p '{"spec":{"minReplicas":1}}'

- 동작을 잘하다가 파드 삭제함
- livenessProbe is Succeed
- readinessProbe is Succeed
- 바로 파드가 다시 올리려함
- startupProbe 는 내부적으로 실행 중 하지만 로그가 찍히는 건 나중부터
- 스프링 애플리케이션 시작 중
- App 초기화 완료
- 완료(startupProbe 이때부터 찍히기 시작)
- 데이터베이스 연결 완료
- App 시작됨
- startupProbe 성공이 찍힘 → 더 이상 시도 안함
- 이제 readinessProbe 는 실패 livenessProbe 는 성공
- ConfigMap 로딩완료
- Data 로딩 완료
- Started AppApplication in 60.11 sec → 완전히 시작됨
- readinessProbe , livenessProbe 둘 다 성공
왜 프로브가 생겼나 → Application 동작에 맞춘 자동화 요구사항에 충족하기 위해서
Application 동작
- App 초기화
- DB 연결
- Spring 초기화
- Jar 실행
- User 초기화
- 초기 데이터 로딩
- 연동 시스템 체크
- DB 데이터 Validation
- App 기동
- App 장애
자동화 요구사항
- App 상태 체크(초기화가 끝났는지)
- 외부 API 접근 금지
[API를 받을 수 있는 상태]
- App 상태 체크(계속 살아있는지)
- 외부 API 접근 금지
- App 재기동
Kubernetes 제공 기능
[App 초기화]
/startup API 호출
Service X↔ Pod
끝나면 앱은 기동 중 → startupProbe 성공
[User 초기화]
/liveness API 호출
App 이 살아 있다면 성공
/readiness API 호출
해당 파드가 준비 됐다는 의미 true 면 Service 와 Pod가 연결됨
[장애 발생 시]
/liveness 실패 → 앱이 죽었다 판단 → 해당 컨테이너 kill 후 재생성
/readiness 를 받아오지 못하니까 연결이 종료됨
여기서 서비스와 파드가 연결된다는 말은
Service가 트래픽을 보낼 대상 Pod를 선택(Selector)해서 라우팅을 시작하는 시점을 의미한다.
Service는 레이블 셀렉터를 기준으로 Endpoint(대상 Pod 목록)을 동적으로 유지함
이때 Pod가 Ready 상태(ReadinessProbe 성공)이여야만 Service가 그 Pod를 엔드포인트로 등록
Service → Endpoint에 Pod IP가 등록됨 → 트래픽 전달 가능 상태
동작 흐름 예시
- Deployment가 Pod 생성
- Pod가 컨테이너 실행 중 (Running)
- readinessProbe가 성공하면 → Service는 해당 Pod의 IP를 Endpoint에 등록
- 클라이언트 → Service ClusterIP → 등록된 Pod 중 하나로 요청 전달
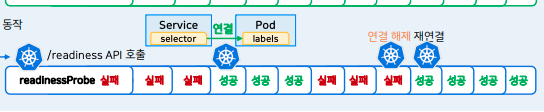
일시적인 장애 상황에서 프로브 잘 쓰기
- Overload
- Leak
- Thread Full
발생
하지만 일시적인 상황인데 프로브 때문에 파드가 재시작하며 서비스 중단이 될 수도 있음
- readinessProbe 는 서비스와 파드 간의 연결을 끊어 복구에 도움을 주니 괜찮
- livenessProbe 이 친구가 문제
- 시간을 잘 선택해 늘려 조금은 여유를 주자
의문점 1
모두 동일한 요청을 보내게 하는 것
같은 걸 보내도 프로브마다 각기 다른의미로 결과를 해석함
실패 시
- startupProbe: 초기에 성공할 때까지 조금 기다리자
- readinessProbe: 트래픽 받지 말고 대기하자
- livenessProbe: 이건 진짜 죽은 거니까 Pod를 재시작하자
의문점 2
“readinessProbe랑 livenessProbe 둘 다 장애 시 실패하는데,
왜 따로 써야 하나요?”
둘이 따로 실패할 때도 있음
응용 과제
강의에서 설명하지 않은 내용도 있어요. 참조 링크를 통해 해결 방법을 찾아보세요.
▶ 응용1 : startupProbe가 실패 되도록 설정해서 Pod가 무한 재기동 상태가 되도록 설정해 보세요.
(여러분들이 가장 많이 겪게될 Pod 에러입니다)
kubectl edit deploy api-tester-1231 -n anotherclass-123

[root@k8s-master ~]# kubectl edit deploy api-tester-1231 -n anotherclass-123
startupProbe:
failureThreshold: 36 -> 5
httpGet:
path: /startup
port: 8080
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
다시 원복하면

동작하는 모습
kubectl edit hpa api-tester-1231-default -n anotherclass-123 -o yaml
이걸로 다시 minReplica 2로 하면

다시 생성됨 파드가
▶ 응용2 : 일시적 장애 상황(App 내부 부하 증가)가 시작 된 후, 30초 뒤에 트래픽이 중단되고, 3분 뒤에는 App이 재기동 되도록 설정해 보세요.
(아래 API를 날리면 readinessProbe와 livenessProbe가 동시에 실패하게 됩니다)
// 부하 증가 - (App 내부 isAppReady와 isAppLive를 False로 바꿈) curl http://192.168.56.30:31231/server-load-on
// 외부 API 실패 curl http://192.168.56.30:31231/hello
// 부하 감소 API - (App 내부 isAppReady와 isAppLive를 True로 바꿈) curl http://192.168.56.30:31231/server-load-off
10초 마다 /readiness 3번 실패하면 트래픽 끊기
60초 마다 /liveness 3번 실패하면 재기동
2025-05-11 23:20:10 2025-05-11T14:20:10.902Z INFO 1 --- [nio-8080-exec-7] DefaultService : [Kubernetes] livenessProbe is Failed-> [System] isAppLive: false
2025-05-11 23:21:10 2025-05-11T14:21:10.903Z INFO 1 --- [nio-8080-exec-4] DefaultService : [Kubernetes] livenessProbe is Failed-> [System] isAppLive: false
3분 뒤에 파드 재기동
▶ 응용3 : Secret 파일(/usr/src/myapp/datasource/postgresql-info.yaml)이 존재하는지 체크하는 readinessProbe를 만들어 보세요.
(꼭 API를 날리는 것만이 readinessProbe 활용의 전부는 아닙니다)
sh -c -f /usr/src/myapp/datasource/postgresql-info.yaml 를 하게 만들기 + 기존의 프로브도 유지
readinessProbe: exec: command:
- sh
- -c
- '[ -f /usr/src/myapp/datasource/postgresql-info.yaml ] && curl -sf http://localhost:8080/readiness' timeoutSeconds: 1 periodSeconds: 10 successThreshold: 1 failureThreshold: 3
마무리
애플리케이션의 동작흐름 중 상태에 따라 자동화를 하기 위한 감시? 테스트? 역할의 Probe에 대해서 배우고 실습해봤다.