[k8s 스터디] #11 Component 동작으로 이해하기
인터넷 강의로 스터디를 진행하고 있는데 강의의 전반부가 끝났다.
전반부는 쿠버네티스의 컨포넌트들이 리소스를 통해 어떻게 쿠버네티스가 컨테이너들을 생성하고 삭제 관리하는지 알아봤다.
이 강의로 쿠버네티스를 처음 배우는 입장이라 강의가 30분이면 1시간 30분은 모르는 내용을 찾아봐야했다.
좀 힘들긴 해도 강의에서 다 떠먹여 줬다면 그냥 강의만 보고 끝났을 것 같기도 해서 공부는 더 잘된 것 같다.
이렇게 전체의 흐름을 빠르게 나가보고 부족한 부분은 다른 강의를 보든 책을 읽든 해서 부족한 부분을 채워야 겠다.
전반부가 끝나고 배웠던 걸 총 정리하는 파트이다.
컨포넌트가 리소스를 가지고 어떻게 동작하는 지 정리했다.
전체 개요

Pod 생성 및 Probe
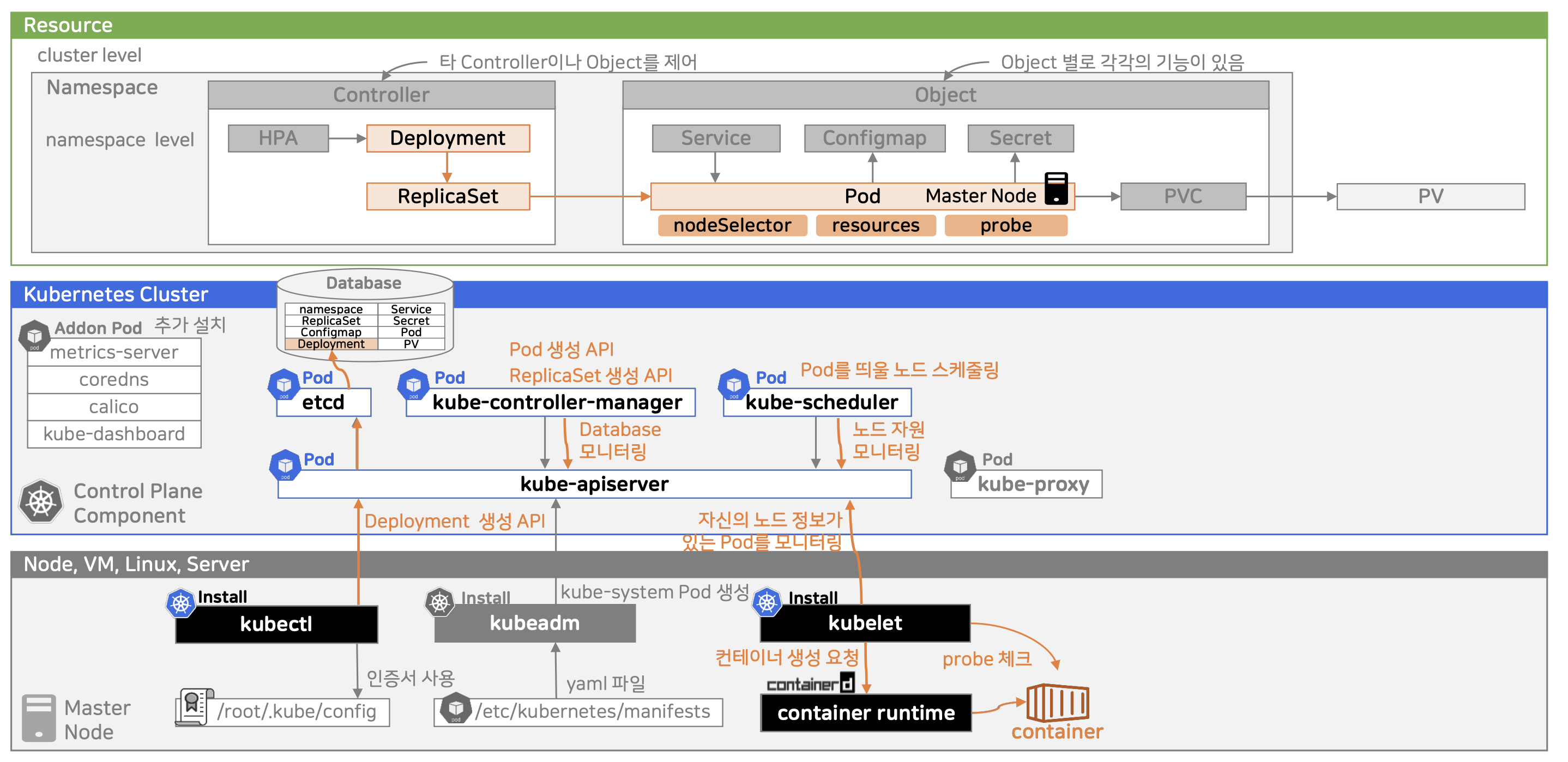
- kubectl apply -f deployment.yaml 명령 실행
- 사용자가 kubectl CLI로 Deployment 리소스를 생성 요청함.
- kube-apiserver가 요청을 받아 처리
- 인증/인가/유효성 검사 후 Deployment 객체를 etcd에 저장함.
- kube-controller-manager가 etcd를 모니터링
- 새로운 Deployment가 감지되면, 설정된 .spec.replicas 수에 따라 ReplicaSet을 생성함.
- ReplicaSet 생성 → Pod 생성 요청
- ReplicaSet은 필요한 수의 Pod가 없으면 kube-apiserver에 Pod 생성 요청을 보냄.
- 이 요청도 etcd에 저장됨.
- kube-scheduler가 대기 중인 Pod를 감지
- 스케줄링되지 않은 Pod를 감지하면, 클러스터의 노드 자원 상태를 기반으로 적절한 Node에 Pod를 할당(Scheduling)함.
- 해당 노드의 .spec.nodeName 필드에 노드 이름이 반영됨.
- Pod가 스케줄된 노드의 kubelet이 감지
- 자신에게 스케줄된 Pod가 있는지 kube-apiserver를 통해 확인.
- 있으면 컨테이너 생성 요청을 container runtime (예: containerd, Docker 등)에 전달.
- 컨테이너 생성 및 실행 시작
- 지정된 이미지로 컨테이너가 실행됨.
- kubelet이 주기적으로 Health Check 수행
- Pod의 Liveness/Readiness probe를 통해 상태를 주기적으로 확인하고, 문제가 있을 경우 재시작 처리.
Service 동작

- 사용자가 NodePort 타입의 Service 생성
- 이 Service 리소스는 kube-apiserver를 통해 etcd에 저장됨
- kube-controller-manager는 selector에 맞는 Pod을 찾아 Endpoint 리소스를 생성 (Pod IP + Port 정보 포함)
- kube-proxy가 서비스 & 엔드포인트 정보를 감시
- kube-proxy는 서비스와 엔드포인트 정보를 주기적으로 감시하고,
- 이에 따라 iptables (혹은 ipvs) 규칙을 설정함:
- 클라이언트가 요청을 보냄
- Node는 OS 레벨에서 iptables 규칙에 따라 이 요청을 가로채고,
- ClusterIP로 리디렉션된 후, 실제로 연결된 Pod IP로 포워딩
- CNI(Calico)가 Pod까지 라우팅 설정
- 이 시점에 트래픽은 노드 내 또는 다른 노드의 Pod IP로 향함
- Calico(혹은 다른 CNI)가 Pod의 네트워크 인터페이스를 만들고, Pod로 트래픽이 올 수 있도록 라우팅 및 경로 생성을 수행
- Pod의 컨테이너에서 앱이 요청 처리
- 컨테이너 내부에서 예: 8080 포트로 Listen 중이라면, 요청을 받아 응답을 생성
서비스 리소스가 만들어지면 apiserver가 해당 리소스를 etcd에 저장함
kube-controller-manager가 해당 리소스의 selector와 일치하는 파드가 있는지 확인해 Endpoint 리소스 만들고 etcd에 저장 → 이벤트 기반으로 Pod를 감시하며 변경시 Endpoint 최신화 해줌 → 이렇기에 우리는 파드가 다른 노드에 만들어진다고해서 따로 신경 쓸 필요가 없어짐
iptables의 역할은 요청을 서비로 포워딩
Service의 Selector로 해당 Pod를 고름 → kube-proxy가
실제 트래픽이 파드로 가게하는 건 Calico(Endpoint를 보고)
Secret 동작
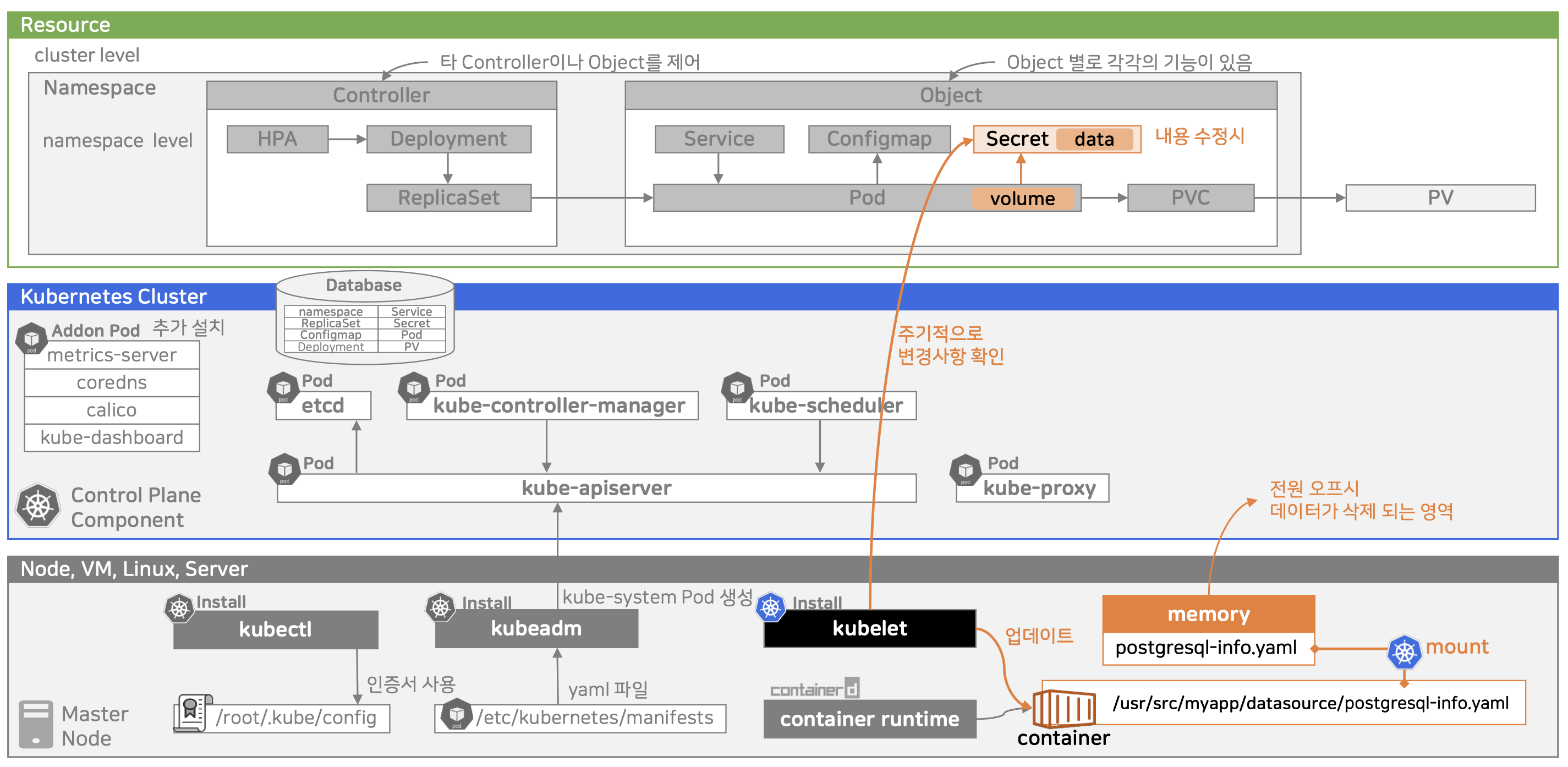
- Secret 생성
- 생성된 Secret 리소스는 etcd에 암호화되어 저장됨(선택적으로 암호화 at rest로)
- kube-apiserver(암호화 주체): Secret 등 민감 리소스를 etcd에 쓰기 전에 암호화함
- kube-apiserver를 통해 CRUD 가능
- 생성된 Secret 리소스는 etcd에 암호화되어 저장됨(선택적으로 암호화 at rest로)
- Pod에서 Secret을 Volume으로 마운트
- kublet이 Secret을 받아 마운트 처리
- kubelet은 kube-apiserver로부터 Pod 스펙을 받고,
- 필요한 Secret이 있으면 API로 Secret 데이터를 조회
- 조회한 데이터를 메모리 상의 tmlpfs 위치에 파일로 생성
- tmlpfs: RAM에 올라가는 임시 파일시스템(이 곳에 저장되어 휘발성임)
- 컨테이너 시작 시 해당 파일이 마운트됨
- 마운트 경로에 파일로 제공
- Pod 내 컨테이너는 마치 일반 파일처럼 해당 내용을 읽을 수 있음
- Secret이 변경되면 Kubelet이 주기적으로 반영
- kubelet은 마운트된 Secret의 변경 사항을 주기적으로 확인
- Secret 리소스가 변경되면, 해당 memory volume의 내용을 업데이트함
HPA 동작
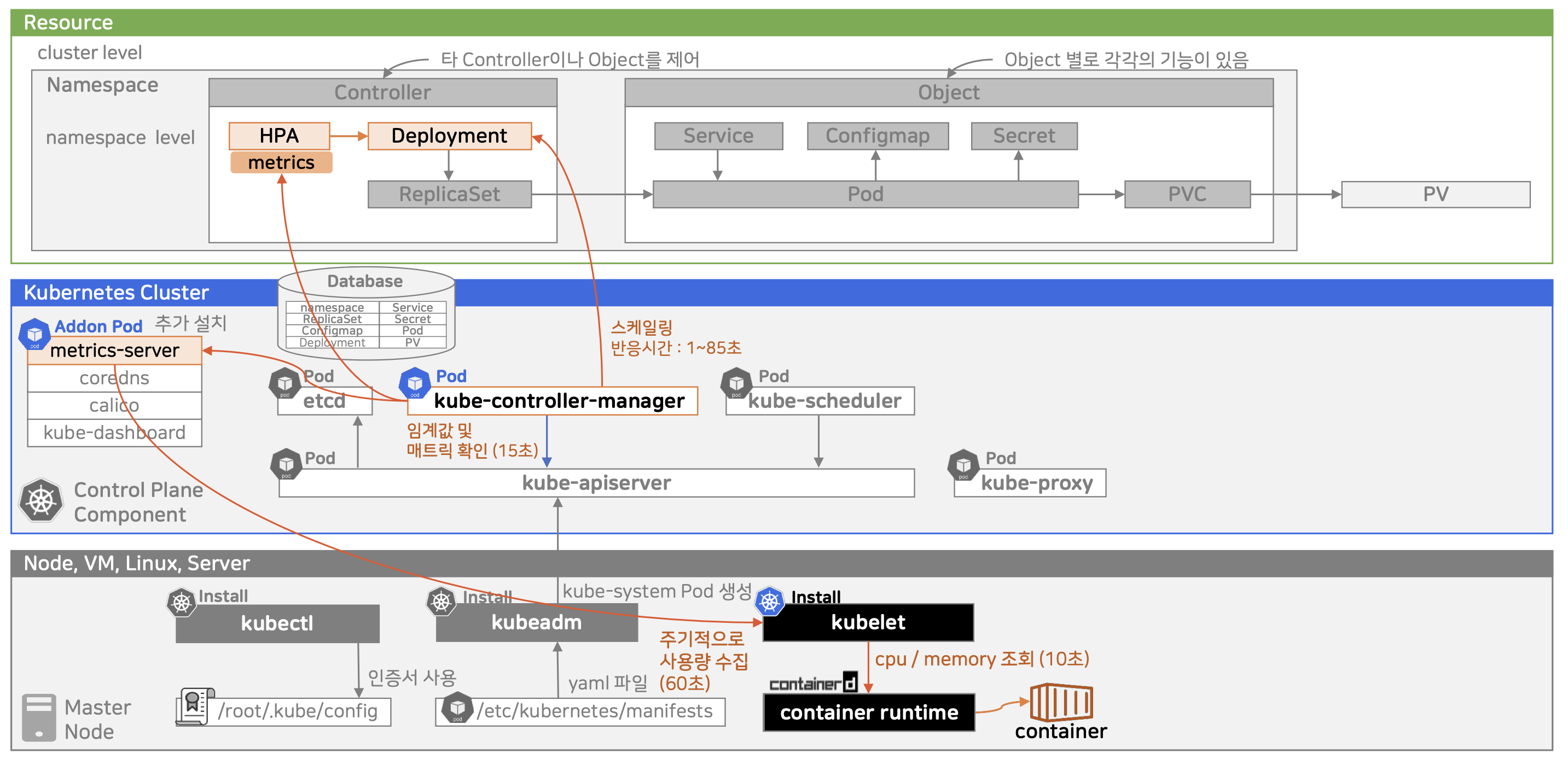
- 컨테이너 사용량 수집(container → kubelet)
- 컨테이너 런타임은 각 컨테이너의 CPU/Mem 사용량 정보를 추적
- kublet은 이 정보를 10초마다 주기적으로 조회함(10초는 고정)
- metrics-server가 kubelet으로부터 메트릭 수집
- metrics-server는 각 노드의 kubelet API에서 수집된 사용량 정보를 60초마다 주기적으로 수집(수정 가능)
- 이 메트릭은 etcd에 저장되지 않으며, 메모리 기반 short-term cache임
- kube-controller-manager가 HPA를 실행
- kube-controller-manager 내부의 HorizontalPodAutoscalerController가
- 모든 HPA 리소스를 15초 주기로 검사함(수정 가능)
- HPA에 정의된 metrics 기준과
- metrics-server가 저장한 실제 사용량을 비교함
- 실제 스케일 반영 됨
- 전체 end to end 반응 시간은 1~85초 사이
요약중 중 궁금한게 생겨서 찾아봤다.
Q1. 수집 주기들은 고정인가요? 바꿀 수 있나요?
| 구성요소 | 기본 주기 | 변경 가능 여부 |
| kubelet → container | 10초 | 고정 |
| metrics-server → kubelet | 60초 | 가능 (Flags) |
| controller-manager → HPA 확인 | 15초 | 가능 (--horizontal-pod-autoscaler-sync-period) |
- metrics-server 주기는 실질적으로 조정 가능하지만, 너무 짧게 하면 부하가 커짐
- kubelet 수집 주기는 변경 불가 (내부 하드코딩)
Q2. 누가 어떤 정보를 왜 수집하나요?
| 주체 | 수집 대상 | 목적 |
| container runtime | 컨테이너의 실제 사용량 (cpu/mem) | 리소스 감시 |
| kubelet | 컨테이너 메트릭 수집 | 노드에서 metrics-server에게 제공하기 위해 |
| metrics-server | kubelet으로부터 metrics 수집 | HPA 등 리소스가 사용할 수 있도록 중앙 집계 |
| kube-controller-manager | metrics-server의 데이터를 비교 | HPA 조건 만족 여부 판단 후 스케일링 실행 |
Q3. 스케일링 결정을 실제로 내리는 주체는?
kube-controller-manager 내부의 HPA 컨트롤러
- 이 컨트롤러가 HPA 리소스를 감시하며,
- metrics-server에서 가져온 사용량과 비교하여,
- scaling 조건이 맞으면 .spec.replicas를 업데이트함
마무리
이렇게 쿠버네티스 내부의 컨포넌트들이 어떻게 동작하는지 확인했다.
이후에는 이제 DevOps 환경을 구축하고 CI/CD를 젠킨스와 쿠버네티스를 통해 구현하는 파트이다.
이후에는 더욱 어려운 내용일 것 같아 집중해서 공부해야겠다.